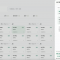
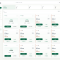
拼豆云掌柜中,豆仓管理双仓实现是怎么做的?我们来讲解一下
近日,Facebook 宣布开源了一个可以通过 Python 和 R 语言使用的预测工具 Prophet。以下是 Facebook 研究博客对该工具的介绍。
预测(forecasting)是一个数据科学问题,也是很多组织机构内许多活动的核心。比如说,像 Facebook 这样的大型组织必须进行能力规划(capacity planning)以有效地分配稀缺资源和目标配置,以便能基于基准对业绩表现进行测量。不管是对于机器还是对于分析师而言,得出高质量的预测都并非易事。我们已经在创建各种各样的业务预测(business forecasts)的实践中观察到了两大主要主题:
- 完全自动化的预测技术可能会很脆弱,而且往往非常不灵活,不能整合有用的假设或启发。
- 能够产生高质量预测的分析师相当少,因为预测是一种需要大量经验的数据科学领域的专业技能。
这两个主题会导致一个结果:对高质量预测的需求往往超出分析师能够得出的预测速度。这个情况是我们创造 Prophet 的动力:我们想要让专家和非专家都能轻松地做出高质量的预测来满足自身的需求。
对于「规模(scale)」的通常考虑涉及到计算和存储,但这些都不是预测的核心问题。我们发现预测大量时间序列(time series)的计算和基础设施问题是相对简单的——通常这些拟合过程可以很容易地并行化,而预测本身也能容易地被存储在 MySQL 这样的关系数据库或 Hive 这样的数据仓库中。据我们观察,「规模」在实践中面临的问题涉及的是由多种预测问题所引入的复杂性(complexity)和在得出预测后如何在大量预测结果中构建信任(trust)。Prophet 已经成为了 Facebook 创建大量可信预测的能力的关键组成部分,这些预测可被用于决策制定甚至用在产品功能中。
Prophet 有什么用?
并非所有的预测问题都可以通过同一种程序(procedure)解决。Prophet 是为我们在 Facebook 所遇到的业务预测任务而优化的,这些任务通常具有以下特点:
- 对于历史在至少几个月(最好是一年)的每小时、每天或每周的观察
- 强大的多次的「人类规模级」的季节性:每周的一些天和每年的一些时候
- 事先知道的以不定期的间隔发生的重要节假日(如,超级碗)
- 合理数量的缺失的观察或大量异常
- 历史趋势改变,比如因为产品发布或记录变化
- 非线性增长曲线的趋势,其中有的趋势达到了自然极限或饱和
我们发现默认设置的 Prophet 能产生往往和经验丰富的预测师得到的一样准确的预测,而所花费的工作却更少。使用 Prophet,如果该预测不令人满意,你也不用局限于一个完全自动化的程序——即使一个没有接受过任何时间序列方法训练的分析师也能够使用各种各样的可轻松解读的参数来改进或调整预测。我们已经发现:通过在特定案例上将自动化预测和分析师参与的预测(analyst-in-the-loop forecasts)结合到一起,它有可能可适用于非常大范围的业务用例。
相关文章